Truth-Tracking TD¶
Introduction¶
Some existing truth discovery algorithms may risk simply finding consensus among sources as opposed to the truth. This might be acceptable in cases where the notion of truth is a bit fuzzy (e.g. in crowdsourcing settings where questions may have a subjective element, what are the ‘true’ answers, and what does ‘trustworthiness’ mean?). In this case truth discovery is perhaps a misnomer, but still appropriate.
For situations where there is a concrete notion of truth at play, the non-consideration of epistemic issues in the existing literature could pose a problem. For example, is it possible for there to be consensus for a position that cannot possibly be true? If so, could a given TD algorithm give false output? Under what conditions can we reasonably expect the true state of the world to be discoverable?
Now, in the fully abstract TD setting – where sources, facts and objects are abstract entities – it seems unreasonable to expect that any real-world ‘truth’ can be found. Some notions of ground truth, domain knowledge, the structure of claimed facts etc seems to be required; otherwise the setting is entirely mathematical and does not reflect the actual world we live in. One way to resolve this could be to develop methods akin to the workings of fact-checking websites, which check claims using trusted reference sources, real-life knowledge, the language used in claims and so on. Regarding the linguistic approach, there seems to be relevant work in NLP [CRC15].
Another approach is the purely formal epistemic one. Here the truth, trustworthiness and the ‘real-world’ are still abstract, but are properly modelled and considered within the TD framework. This allows one to investigate the questions above without needing to consider domain knowledge etc. Instead of trying to find the true world from an isolated set of claims (as would be done by a fact-checking site), we can look at whether a TD algorithm can find the truth in principle, given inputs that conform to the true world in some way. This has been done successfully for judgment aggregation, belief merging and other areas (citation needed), where truth-tracking algorithms have properties which ensure the truth is found under appropriate conditions.
TODO in this document¶
Review what approaches to truth-tracking have been looked at in JA, belief revision (and argumentation?)
Write out the goals and research questions for this piece of work, based on the ideas in existing work
A key question, not tackled so far to my knowledge, is whether truth-tracking can be achieved in the presence of unreliable sources.
Develop epistemic framework for TD and a truth-tracking axiom
Investigate examples of where truth-tracking does and doesn’t hold
Truth Discovery Framework¶
Before spelling out ideas for truth-tracking for TD, let us outline the TD framework. We consider fixed disjoint sets \(\S, \F\) and \(\O\) of sources, facts and objects. A mapping \(\obj: \F \to \O\) associates each fact with an object. We also consider a set \(\V\) equipped with a total order \(\vle\).
The input to TD is a relation between sources and facts, which indicates which claims are made.
Definition (Network)
A network is a relation \(N \subseteq \S \times \F\) such that
\(N\) is non-empty and finite.
For all \(s \in \S\) and \(o \in \O\), there is at most one \(f \in \obj^{-1}(o)\) such that \((s, f) \in N\).
Let \(\N\) denote the set of networks.
An operator maps a network to an assessment of source reliability and fact believability.
Definition (TD operator)
A TD operator is a mapping \(T: \N \to (\S \cup \F \to \V)\).
That is, for each network \(N\), \(T(N)\) is a mapping which assigns each source and fact a value in \(\V\).
Truth-tracking for Truth Discovery¶
To speak of truth-tracking or truth-approximation, we need to represent the true world in some way. Up front it seems there are several sensible possibilities for the definition of worlds. A world may prescribe the true facts for each object, or a measure of belief for each fact. Source trust could also be encoded in the state of the world, in which case each source has a single fixed trustworthiness level (this would be something closer to reliability than trust, which is usually a relation between agents as opposed to an absolute measure). 4
Here we will consider a possible world to be an assignment of trust scores and an assignment of a true fact to each object. We can view such worlds as mappings \(\S \cup \F \to \V\), so as to match the output of TD operators.
Definition (Possible worlds)
A possible world in a truth discovery problem is a mapping \(w : \S \cup \F \to \V\) such that 5
\(w(\F) \subseteq \{0, 1\}\)
For each object \(o \in \O\), there is exactly one \(f \in \obj^{-1}(o)\) such that \(w(f) = 1\).
That is, facts may only recieve scores of 0 or 1, and each object has a single fact with score 1.
We can sketch out several ideas for truth-tracking postulates, based on ideas from the related areas.
Formulation 1¶
Idea: If in the limit the input data matches the real world \(w\), the operator finds \(w\) (c.f. [BGS19]).
The question of when input ‘matches’ a world is not trivial in our TD model (compared to propositional logic formulations in belief revision/merging), since in general we do not label sources strictly trustworthy or untrustworthy, but allow a continuum of trust values. This means that i) most worlds will not have any networks perfectly matching them (e.g. consider all sources are unreliable and choose facts at random), and ii) a network may equally well match several similar worlds.
The first point suggests we should have a measure of compatibility between worlds and networks which takes a continuum of values, not just true vs false. This is addressed in the following definition.
Definition (Comptability function)
Given a set of worlds \(\W\), a compatability function \(\varphi : \W \to (\N \to [0, 1])\) gives the compatability between worlds and networks. 6 That is, for each \(w \in \W\) and \(N \in \N\), \(\varphi_w(N)\) is a measure of how compatible the claims in \(N\) are with the world \(w\), with 0 and 1 representing minimally and maximally compatiblity respectively.
Now we address the issue of when a world matches a sequence of inputs in the limit.
Definition (Approximating sequence)
Let \(\mathcal{X} = \{X=(N_k)_{k \in \Nat} : \forall k \in \Nat, N_k \subseteq N_{k+1} \}\) be the set of ‘widening’ sequences of TD networks (i.e. the claims in the \(k\)-th network include those from all previous networks).
Define a relation \(\mathcal{A}_\varphi \subseteq \mathcal{X} \times \W\) by \((X, w) \in \mathcal{A}_\varphi\) iff \(\lim_{k \to \infty}{\varphi_w(N_k)} = 1\). We say \(X\) approximates \(w\) in this case. Write \(\mathcal{A}_\varphi(X) = \{w \in \W : (X, w) \in \mathcal{A}_\varphi\}\) for the set of worlds which \(X\) approximates.
That is, \(X\) approximating \(w\) means that (in the limit) the network \(N_k\) is maximally compatible with the true world being \(w\). Note that \(X\) may approximate multiple distinct worlds; in this case the worlds are indistinguishable from the point of view of \(X\) given the compatibility measure \(\varphi\).
The truth-tracking postulate can now be stated: an operator should, in the limit, find the world which the input sequence \(X=(N_k)_{k \in \Nat}\) approximates (if such a world is unique).
Axiom (Truth-tracking 1)
A TD operator \(T\) is truth-tracking if for any \(X=(N_k)_{k \in \Nat} \in \mathcal{X}\): 7
Note that this axiom says nothing in cases where \(|\mathcal{A}_\varphi(X)|>1\).
Problems with formulation 1¶
The first difficulty lies in defining \(\varphi\). The most interesting case is the probabilistic one, where \(\varphi_w(N)\) represents the probability that the network \(N\) would arise when the true world is \(w\); here \(w(s)\) is (something like) the probability that a source’s claim is true, and \(w(f)\) is the probability that \(f\) is the true fact for its object.
However, it seems difficult for \(\varphi_w(N_n) \to 1\) to be satisfied when there are untrustworthy sources. Indeed, consider the worst case where all sources are completely unreliable and choose facts uniformly at random for each object. 8 Then any network is equally likely, so we can never get a \(N\) with high \(\varphi_w(N)\).
This could be solved by dividing by the maximum probability across \(\N\) in the definition of \(\varphi_w(N)\), but this needs further thought.
There is also no account of the sparsity of TD datasets (most sources only make claims for a few objects). If \(X\) approximates the true world \(w\) but each source makes few claims, it is unreasonable to expect \(T\) to find the true world. As above, this could be solved by taking the completeness (‘anti-sparsity’?) of \(N\) into account in the definition of \(\varphi_w(N)\).
Another problem is that this formulation implicitly assumes \(\S\), \(\F\), \(\O\) should be infinite. Indeed, the ‘widening’ requirement in a finite domain implies that \(N_k\) eventually becomes constant, which makes taking limits redundant. Consequently we need to consider pointwise convergence of \(T(N_k)\) (since some sources/facts will not appear in \(N_k\) until \(k\) is sufficiently large), and the axiom gets messy.
Formulation 2¶
Idea: \(T(N)\) is closer to the true world than each source’s beliefs are. That is, \(T\) provides an improvement over the individual source inputs (either absolutely or on average). C.f. [Cev14]. According to their terminology, this is more like truth approximation than truth tracking. For this formulation, we assume \(\S, \F\) and \(\O\) are finite.
The missing ingredients are:
A distance measure \(d\) between \(T(N)\) and worlds \(w\).
A distance measure \(d'_N\) between source and worlds \(w\), with respect to a network \(N\).
Options for \(d\) include:
\(\ell_p\) distance: for \(p>0\), writing \(g = T(N)\),
\[d(g, w) = \left(\sum_{z \in \S \cup \F}{\left|g(z) - w(z)\right|^p} \right)^{\frac{1}{p}}\]This assumes \(\V \subseteq \R\).
The number of objects which \(T\) selects a false fact. Specifically, enumerate \(\O=\{o_1,\ldots,o_n\}\) and for a function \(g: \S \cup \F \to \V\), write \(v_g = (f_1,\ldots,f_n)\) where \(f_i = \text{argmax}_{f \in \obj^{-1}(o_i)}{g(f)}\). Then we can set \(d(g, w) = d_H(v_g, v_w)\) where \(d_H\) denotes Hamming distance.
For \(d'_N\), we could apply a similar Hamming distance idea: look at the number of objects where \(s\) claims a fact in \(f \in \obj^{-1}(o)\) which has \(w(f) = 0\).
The truth tracking/approximation axiom will put an upper bound on \(d(T(N), w)\) in terms of the \(d'_N(s, w)\).
Axiom (Truth-tracking 2)
Let \(d: (\S \cup \F \to \V)^2 \to \R_{\ge 0}\) be a distance measure on functions \(\S \cup \F \to \V\), let \(\W\) be the set of worlds, and for a network \(N\) let \(d'_N: \S \times \W \to \R_{\ge 0}\) be a distance measure between sources and worlds.
Let \(G: \bigcup_{n \in \Nat}{\R_{\ge 0}^n} \to \R_{\ge 0}\) be a function which aggregates tuples of (non-negative) numbers. Then \(T\) is truth-tracking wrt \(G, d, d'\) if for each network \(N\) and world \(w\): 9
Examples for \(G\) include taking the minimum (\(T(N)\) must be at least as close to the truth as each source’s claims) or mean (\(T(N)\) must be at least as good as the ‘average source’).
Problems with formulation 2¶
Intuitively the idea is not too complex, but technically the axiom is inelegant and seems difficult to work with.
It seems one also needs to take care to ensure the comparison between distances from \(d\) and \(d'\) make sense. These distance measures should somehow be representing the same thing, so that the distances are on the same scale.
Another problem is that, depending on the choice of \(d\), it may not consider how well \(T(N)\) reflects the true source trustworthiness levels.
Formulation 3¶
Idea: if \(N\) is more compatible with \(w'\) than \(w\), then \(T(N)\) is closer to \(w'\) than it is to \(w\).
Axiom (Truth-tracking 3)
\(T\) is truth-tracking if for all networks \(N\) and worlds \(w, w'\) it holds that
where \(d: (\S \cup \F \to \V)^2 \to \R_{\ge 0}\) is a distance measure.
Intuitively, this axiom says that \(T(N)\) should be close worlds that are highly compatible with \(N\). Thus it seems an obvious choice is to take \(T(N) \in \text{argmax}_{w \in \W}{\phi_w(N)}\); then \(T(N)\) corresponds exactly to the (one of the) maximally compatible worlds.
I think there is probably some simple property linking \(\phi\) and \(d\) which guarantees this argmax operator satisfies the axiom, but I cannot figure it out.
Formulation 4¶
Idea: take a simpler view on the possible worlds and constraint the compatibility function \(\phi\) to just 0 or 1. Note that in some sense this goes against the motivation behind Formulation 1.
Write \(\mathcal{Z} = \V^{\S \cup \F}\) for the set of TD operator outputs (so that an operator is a mapping \(\N \to \mathcal{Z}\)).
Definition (Epistemic model)
An epistemic model is a tuple \(M = \tuple{\W, \vDash, e}\) where \(\W\) is a set of worlds, \({\vDash} \subseteq \W \times \N\) is an entailment relation between worlds and networks, and \(e: \W \to \mathcal{Z}\) is an embedding of worlds in the TD output space.
Note that \(\W\) here is not fixed (i.e. we are not using the definition of possible worlds given before formulation 1).
Intuitively, \(w \vDash N\) means that \(N\) is compatible with the true world being \(w\) (c.f. \(\phi_w(N) = 1\) in formulation 1). Write \([N] = \{w \in \W : w \vDash N\}\).
Consider a fixed epistemic model \(\tuple{\W, \vDash, e}\). Given an operator \(T\), a network \(N\) and a distance measure \(d: \mathcal{Z}^2 \to \R_{\ge 0}\), we can define a total preorder \(\preccurlyeq_N^T\) on \(\W\) by
Then \(\min(\W, \preccurlyeq_N^T)\) is the set of worlds ‘closest’ (via the embedding \(e\)) to the output of \(T\). We can consider these to be the worlds which \(T\) picks out as the ‘best’ (e.g. most probable). The fact that there may be several minimal worlds represents the uncertainty as to which one is actually the unique true one.
Two natural properties \(T\) may satisfy (for a given \(N\)) are the following:
(S) is a sort of ‘soundness’: every world which \(T\) finds is indeed a model of \(N\). (C) is a sort of ‘completeness’: every model of \(N\) is found by \(T\).
Example
Set
(again, assuming \({0, 1} \subseteq \V\)).
Here a world is a set of absolutely trustworthy sources and absolutely true facts. A network is compatible with a world iff trustworthy sources never claim false facts (note: nothing can be said about the claims of untrustworthy sources).
This representation in unrealistic when it comes to modelling the real world, since there is no uncertainty in the source reliability assessment. However this might be okay, as the uncertainty can be encoded in \(T(N)\). E.g. \(T_N(s)\) could represent \(P(\{w: s \in S_w\})\), i.e. the probability (or ‘degree of belief’, or something else…) that we are in a world where \(s\) is absolutely trustworthy. A score like \(T_N(s) = 0.5\) represents \(s\) being ‘half-reliable’, in the sense that worlds where \(s\) is trustworthy vs untrustworthy are equally likely. Compare this to the Bovens-Hartmann model of source reliability described in [MSH20], which is similar.
Problems with formulation 4¶
I think the idea behind this formulation and the complementary (S) and (C) properties are quite nice, but it seems difficult to work with in practice.
More importantly, care needs to be taken to ensure that \(d(e(w), T(N))\) is actually meaningful; otherwise \(\min(\W, \preccurlyeq_N^T)\) might not really be a good representations of the likely worlds from the point of view of \(T\).
For example, consider the epistemic model of the example above, and consider the network \(N\) of Figure 1.
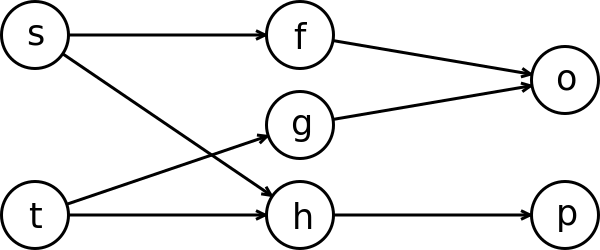
Figure 1¶
Consider an operator \(T\) with \(T_N(h)=1\) and which assigns a score of 0.5 to all other nodes, for this seems like a sensible output for the network in question.
We have
Using the \(\ell_p\) distance \(d(\alpha, \beta) = \left(\sum_{z \in \S \cup \F}{|\alpha(z) - \beta(z)|^p}\right)^{\frac{1}{p}}\) – which seems natural for a distance measure between functions – we have \(d(e(w), T(N)) = 2^{\frac{2}{p} - 1}\) for all \(w \in \W\). In particular, \(\min(\W, \preccurlyeq_N^T)=\W\), so ‘completeness’ (C) is trivially satisfied, and ‘soundness’ (S) is not.
Since the distance between (embeddings of) worlds and \(T(N)\) is constant, the notion is mostly useless. We might need a more sophisticated way to measure which set of worlds \(T(N)\) represents.
Alternatively, we could ditch the distance measure \(d\) and consider replacing \(\min(\W, \preccurlyeq_N^T)\) with a set of worlds \(R(T(N)) \subseteq \W\) – i.e. have a function \(R: \mathcal{Z} \to 2^\W\) which gives the set of worlds which \(T(N)\) best represents. The distance-based approach above is a special case of this, but there may be other choices of \(R\) which are more appropriate.
Other ideas¶
If the agents have some particular properties (e.g. independence, reliability) which make the input look like the real world, the operator finds it (Condorcet, belief merging). This seems harder to generalise to TD, since we need to account for unreliable sources.
- 1
Note that this is the actual majority rule, which chooses the alternative with a strict majority. It is distinct from the plurality rule (which I previously called majority) in general, although the two conicide when only two alternatives are available.
- 2
Their voting rules are randomised, i.e. for each input profile they return a probability distribution over rankings.
- 3
Here \(x_i\) denotes the judgement set of the \(i\)-th agent, and \(x_i^{(j)}\) denotes the judgement of the \(i\)-th agent on the \(j\)-th proposition in the agenda.
- 4
The framework could be generalised a bit to make the single trustworthiness value less restrictive; e.g. if trust scores are values in \(\V'\) which is only partially ordered. Then incomparable elements of \(\V'\) could represent trustworthiness/reliability on different topics.
- 5
Here we assume \(\{0, 1\} \subseteq \V\).
- 6
Note that the totally-ordered set \(\V\) is used elsewhere for assessments of trust and belief, but \([0, 1]\) is chosen here for simplicity.
- 7
Here we speak of the pointwise limit a sequence of functions. This is defined as follows: a sequence \((g_k)_{k \in \Nat}\) of functions from a common domain \(D\) into \(\V\) converges pointwise to \(G: D \to \V\) iff for every \(x \in D\) we have \(\lim_{k \to \infty}{g_k(x)} = G(x)\).
In turn, this relies on taking the limit of the \(\V\)-valued sequence \((g_k(x))_{k \in \Nat}\). This can be defined in the usual way if \(\V\) is a bounded metric space for some distance function \(d: \V \times \V \to \mathbb{R}_{\ge 0}\). In most cases we will take \(\V \subseteq \mathbb{R}\) bounded, anyway…
- 8
Note that this could be worse than the case of malicious sources, who always claim false facts. In this case we at least know that the claims are false, whereas for random guessers no information is gained.
- 9
Here we enumerate \(\S = \{s_1,\ldots,s_m\}\).
Social Choice¶
In binary voting, Condorcet’s Jury Theorem gives an epistemic account of majority voting. 1
Theorem (Condorcet’s Jury Theorem)
Suppose \(n\) agents vote for either \(\alpha\) or \(\neg \alpha\), and WLOG assume \(\alpha\) is the truth. Then if each agent votes for the correct choice \(\alpha\) with probability \(p > 0.5\) and each agent is independent, then the probability that \(\alpha\) is chosen by the (strict) majority operator approaches 1 as \(n \to \infty\).
The conditions of the theorem are quite strong (certainly for our purposes, assuming each source has reliability greater than 0.5 is unacceptable). Extensions of the theorem with weaker conditions exist; see the discussion and references in [EKM+10] for further reading. A relevant excerpt from that paper is the following:
Condorcet’s model is generalised in the voting context to \(m > 2\) alternatives by Mallows’s model. In [CPS16] the authors consider two aspects of truth-tracking in Mallows’s model and more general noise models.
Firstly, the authors claim that many voting rules find the correct ranking as the number of voters \(n\) goes to infinity and votes are drawn from Mallows’s model (presumably this is because \(p > 1/2\)). The question of whether a particular rule has this property is therefore uninteresting. They instead look at how quickly the rule finds the truth: how many voters are required to find the true ranking with probability \(1 - \epsilon\), for some small \(\epsilon > 0\). 2 For example, Kemeny’s rule requires the fewest amongst all other rules, and the plurality rule requires a number of voters exponential in the number of alternatives \(m\). Another class of rules generalising Condorcet consistency requires a number of voters logarithmic in \(m / \epsilon\) (this is an asymptotic upper and lower bound).
Secondly, they consider when a voting rule finds the truth in the limit for more general families of noise models, which are parametrised by a metric on the set of rankings. In particular, they look at two classes of voting rule and characterise the metrics for which the rules are guaranteed to find the truth in the limit.
Maybe something along these lines could be helpful for truth-tracking truth discovery. We could generalise the probabilistic model to account for untrustworthy or adversarial sources (i.e. allow different reliability rates \(p_s \in [0,1]\) for each source in Mallows’s model), and instead of ‘how many voters?’, ask ‘how much trustworthiness?’ is required to find the truth within some margin of error. Maybe this could be the number or proportion of untrustworthy sources, or some aggregation of error rates across sources. Maybe this idea could be developed for a fixed number of sources. Alternatively, we could ask which conditions must be placed on the \(p_s\) values in order for it to be possible to find the truth in the limit.