Belief Revision¶
Information Revision: The Joint Revision of Belief and Trust (2020)
Belief Merging Operators as Maximum Likelihood Estimators (2020)
The Epistemic View of Belief Merging: Can We Track the Truth?. (2010)
Aggregation in Multi-Agent Systems and the Problem of Truth-Tracking (2007)
Reasoning about belief, evidence and trust in a multi-agent setting (2017)
Information Revision: The Joint Revision of Belief and Trust (2020)¶
(Yasser, Ammar and Ismail, Haythem O.)
Summary:
When receiving information from multiple sources, belief revision depends on trust, and trust revision depends on beliefs
Authors propose to revise both trust and belief at the same time (‘information revision’)
They give a general framework for information revision, and state some postulates
Background:
Authors argue that belief revision depends on trust: the extent to which we should revise existing beliefs depends on how much we trust the source of new information
But trust revision also depends on beliefs: a source may become less trusted if it conflicts with existing beliefs, or more trusted if it confirms them
Belief and trust revisions have cascading effects: if a trusted source \(\sigma_1\) conveys \(\phi\) which conflicts with \(\psi\), we may decrease trust in source \(\sigma_2\) who previously conveyed \(\psi\), and possibly decrease belief in another statement \(\xi\) conveyed by \(\sigma_2\) and so on…
In their words: Hence, we contend that belief revision and trust revision are so entangled that they need to be combined into one process of joint belief-trust revision
Framework:
Def: An Information grading structure is \({G} = ({D}_b, {D}_t, \prec_b, \prec_t, \delta)\), where
\({D}_b\) and \({D}_t\) are sets of belief and trust levels respectively, totally ordered by \(\prec_b\) and \(\prec_t\)
\(\delta \in {D}_t\) is the ‘default’ trust level
Def: An Information structure is \(({L}, {C}, {S}, {G})\), where
\({L}\) is a logical language with Tarskian consequence operator \(Cn\) (and which includes negation)
\({C}\) is a finite cover of \({L}\), i.e. a finite collection of subsets of \({L}\) whose union is \({L}\). Each element of \({C}\) represents a topic
\({S}\) is a finite set of sources
\({G}\) is a grading structure
Def: An Information state over an information structure is \(K = ({B}, {T}, {H})\), where
\({B}: {L} \hookrightarrow {D_b}\) is a partial function assigning formulas a degree of belief
\(\mathcal{T}: S \times C \hookrightarrow D_t\) is a partial function assigning a degree of trust to sources and topics
\(H \subseteq S \times L\) is the history of statements received
A filter is a set \(F \subseteq L \times S\); it determines which statements received will actually make it into the history: new information \(\phi\) from source \(\sigma\) is only added to the revised information state if \((\phi, \sigma) \in F\)
\(For(B) = \{\phi \mid \exists d_b \in D_b : (\phi, d_b) \in B\}\) is the set of formulas in \(B\) (ignoring degrees of belief). This represents the belief base associated with \(K\).
Def: \(\phi\) is more entrenched in \(K_2\) than \(K_1\), denoted \(K_1 \prec_\phi K_2\), if either \(\phi\) is a consequence of \(For(B(K_1))\) and not \(For(B(K_1))\), or if \(\phi\) is in both belief bases but held to a higher degree of belief in \(K_2\).
Def: Source \(\sigma\) being more trusted on topic \(T\) in \(K_2\) than in \(K_1\), written \(K_1 \prec_{\sigma,T} K_2\) is defined similarly.
Support and relevance:
The support graph associated with \(K\) has nodes consisting of sources present in the history \(H\) and the formulas in the belief base and history.
Bidirectional edges between sources and formulas they provided, and an edge from \(\phi\) to \(\psi\) if there is a set \(\Gamma \subseteq L\) such that \(\phi \in \Gamma\), \(\psi \in Cn(\Gamma)\) and \(\psi \notin Cn(\Delta)\) for all \(\Delta \subsetneq \Gamma\).
Similar to TD network, but with additional edges between ‘facts’ which support others. Also, no edges relating contradictory facts (i.e. \(\phi\) and \(\neg\phi\))
Notion of relevance defined in terms of the support graph plus some quite technical condition
Interesting that relevance does not depend on the topics. One might naturally expect that \(\phi\) is relevant to \(\psi\) if they are both contained within some common topic \(T\)
Postulates:
Authors do not consider totally malicious sources, whose conveyance of \(\phi\) should decrease belief in \(\phi\) or increase belief in \(\neg\phi\). Perhaps this is a limitation, but we made the same assumption in the AAMAS 2019 extended abstract in the Monotonicity axiom.
Plain English descriptions of the postulates, where \(K \ltimes (\phi, \sigma)\) denotes the revised information state after revision by \(\phi\), on topic \(T\), received from source \(\sigma\).
\(K \ltimes (\phi, \sigma)\) is an information state
If \(K\) does not give a trust value for \((\sigma, T)\) (via the partial function \(\mathcal{T}\)), then the trust value in \(K \ltimes (\phi, \sigma)\) is the default \(\delta\)
The revised belief base is consistent (its consequences are not the whole language \(L\))
If \(\phi\) is inconsistent then \(\sigma\) is not more trusted on topic \(T\) in \(K \ltimes (\phi, \sigma)\) then in \(K\)
If \(\phi\) is less entrenched in \(K \ltimes (\phi, \sigma)\) then the belief base in \(K\) must have been inconsistent
\(\neg\phi\) never becomes more entrenched after revision
If some source \(\sigma'\) becomes more trusted on \(T\), then either \(\sigma' \ne \sigma\) and \(\sigma'\) is supported by \(\phi\), or \(\sigma'=\sigma\) and there is a subset of the belief base \(\Gamma\) which implies \(\phi\) and does not depend on information coming from \(\sigma\)
If some source \(\sigma'\) becomes less trusted on \(T\), then either \(\phi\) is in the revised belief base and \(\sigma'\) is \(\neg\phi\) relevant, or \(\sigma'=\sigma\) but there is a subset of the revised belief base which implies \(\neg\phi\)
If some formula \(\psi \ne \phi\) becomes more entrenched, then \(\psi\) is supported by \(\phi\)
If some formula \(\psi\) becomes less entrenched, either \(\psi\) is \(\neg\phi\) and \(\phi\) is in the revised belief base or \(\neg\phi\) became less entrenched; or \(\psi\) is \(\phi\) relevant and \(\phi\) is not in the revised belief base or \(\phi\) became less entrenched
Rest of the paper:
Some properties that follow from the postulates
Discussion of AGM postulates that are not guaranteed in this setting (mostly by design due to the nature of revision based on trust)
Somewhat contrived extended example
Qualms:
The authors claim a ‘forgetful’ filter \(F \ne L \times S\) simulates ‘realistic scenarios where an agent does always not remember every piece of information that was conveyed to it. But is that really the case? From the equation at the top of p152, the revised history \(H(K \ltimes_F (\phi, \sigma))\) is always a superset of \(H(K)\) (equal iff \((\phi, \sigma) \notin F\)). So \(F\) only simulates an agent forgetting information immediately, and not ever adding it to its information state.
Belief Merging Operators as Maximum Likelihood Estimators (2020)¶
(Everaere, Patricia and Konieczny, Sebastien and Marquis, Pierre)
Summary:
Looks at how belief merging operators can be seen as maximum likelihood estimators in different noise models
Takes the epistemic view of merging: there is a true world \(\omega^*\), and agents’ belief bases are noisy estimates of it
MLE operators:
A noise model tells us the probability that a world \(\omega\) is a model of belief base \(K_i\) for agent \(i\), given the true world \(\omega^*\) and an integrity constraint \(\mu\). This gives us a probability distribution over profiles \(E\) for each \((\omega^*, \mu)\).
A merging operator \(\Delta\) is an MLE operator for noise model \(P\) if \([\Delta_\mu(E)] = \argmax_{\omega}{P_{\omega,\mu}(E)}\), where \(P_{\omega,\mu}(E)\) is the probability of observing profile \(E\) when the true world is \(\omega\) with integrity constraint \(\mu\).
An independence assumption on the noise model implies that any MLE operator satisfies most (all but two) of the standard IC postulates.
A couple of standard merging operators are MLE operators for some noise model
Authors now look at two specific noise models (“world swap” and “atom swap” noise) and find that some standard merging operators are ML estimators for them.
Experimental results:
For each of the two noise models, authors investigate how well the MLE operators do in practise
Generate a true world \(\omega^*\). Integrity constraint is a tautology
Set the parameters of the noise models (a single number \(p\) for both world- and atom-swap)
For different values of the number of agents \(n\):
Generate 1000 profiles
Look at the proportion of profiles for which \([\Delta(E)] = \{\omega^*\}\) (where \(\Delta\) is the appropriate MLE operator for the noise model)
Plots of the success rate for different noise levels in each model. Idea is to see how well operators cancel the noise: if they do it well then few agents should be required to get good accuracy. Authors claim this is the case.
Belief revision with unreliable observations (1998)¶
(Boutilier, Craig and Friedman, Nir and Halpern, Joseph Y)
Truth-Tracking by Belief Revision (2019)¶
(Baltag, Alexandru and Gierasimczuk, Nina and Smets, Sonja)
Looks at whether iterated revision methods can ‘learn’, i.e. converge to true beliefs
Universality: “whether or not a particular belief revision method is able to learn every- thing that in principle is learnable”
Framework:
Set of possible worlds \(S\) and observable propositions \(\mathcal{O} \subseteq 2^S\) (that is, each proposition is represented by the set of worlds in which it is true).
\(\mathbb{S} = (S, \mathcal{O})\) is called an epistemic space
For \(\preceq\) a total preorder on \(S\), \(\mathbb{B}_\mathbb{S} = (S, \mathcal{O}, \preceq)\) is called a plausability space. Here \(s \preceq t\) means the agent considers \(s\) to be more plausible than \(t\).
Knowledge and belief:
An agent ‘knows’ only the tautologies: we have a modality \(K\) such that for any proposition \(p \subseteq S\), \(Kp\) iff \(p = S\), i.e. if \(p\) is true in every possible world.
In a ‘standard plausibility space’ (when \(\preceq\) has no infinitely descending chain), belief is defined as \(Bp\) iff \(\min_\preceq{S} \subseteq p\), i.e. if \(p\) holds in all the most plausible worlds
The authors do not restrict to standard plausibility spaces. In general, the definition is \(Bp\) iff there is \(w \in S\) such that for all \(u \preceq w\) we have \(u \in p\). That is, there is a ‘threshold’ world \(w\) such that \(p\) holds for all worlds at least as plausible as \(w\).
Observations
A data stream is a sequence \(\vec{O} = (O_n)_{n \in \mathbb{N}}\) of observables. A data sequence is a finite tuple of observables.
\(\vec{O}\) is sound wrt \(s \in S\) if \(s \in O_n\) for each \(n \in \mathbb{N}\). \(\vec{O}\) is complete wrt \(s\) if \(s \in O\) implies \(s \in O_n\) for some \(n\).
Learning methods:
\(L\) maps an epistemic space \(\mathbb{S}\) and data sequence \(\sigma\) to a set of worlds, interpreted as a conjecture for the possible true worlds given the new information in \(\sigma\). That is, \(L(\mathbb{S}, \sigma) \subseteq S\).
Properties of learning methods are defined as follows. Write \(\sigma=(\sigma_1,\ldots,\sigma_n)\).
Weakly data-retentive: \(L(\mathbb{S}, \sigma) \subseteq \sigma_n\), i.e. the last piece of new data in \(\sigma\) is always believed (entailed by each world in the conjecture).
Strongly data-retentive: \(L(\mathbb{S}, \sigma) \subseteq \sigma_i\) for each \(1 \le i \le n\), i.e. every new piece of data is believed (alternatively, the conjunction of the new data is entailed by each world in the conjecture).
Convervative: \(\emptyset \ne L(\mathbb{S}, \sigma) \subseteq p\) implies \(L(\mathbb{S}, \sigma) = L(\mathbb{S}, \sigma * p)\), where \(p \in \mathcal{O}\) and \(*\) denotes concatenation. That is, when receiving new data which was already entailed by the previous conjecture, nothing changes.
Data-driven: conservative and weakly data-retentive
Memory-free: if \(L(\mathbb{S}, \sigma) = L(\mathbb{S}, \sigma')\) then \(L(\mathbb{S}, \sigma * p) = L(\mathbb{S}, \sigma' * p)\). That is, the conjecture depends only on the most recent conjeture and new data, not on the previous data received.
Rest of the paper… (skimmed)
Defines belief revision in plausibility spaces and how this induced a learning method, given some initial plausibility ordering.
Looks at properties similar to the above for belief revision functions.
A learning method \(L\) identifies a world \(s\) in the limit if for every sound and complete data stream there is a finite time after which only the singleton set \(\{s\}\) is output as the conjecture. That is, \(L\) eventually singles out \(s\) as the only possible world. \(L\) identifies an epistemic space if it identifies all its worlds.
\(L\) is universal if it can identify all epistemic spaces that are identifiable by some learning method.
Limitation of this: requires the data stream to be sound and complete. This is not reasonable in real life: there may be false data (failure of soundness) and omission of truths (failure of completeness).
Authors look at some existing belief revision operators wrt universality.
Go on to look at negation-closed epistemic spaces, where \(\mathcal{O}\) is closed under complementation. That is, each observable \(p\) has a negation \(S \setminus p\).
Authors then relax sound and complete stream requirements to fair streams: any false information is eventually corrected (but completeness is still required). That is, \(\vec{O}\) is fair with respect to a world \(s\) if there is \(N \in \mathbb{N}\) such that \(s \in O_n\) for all \(n \ge N\), and \(s \notin O_k\) for some \(k\) implies there is \(n\) such that \(\overline{O_k} = O_n\).
This allows learning methods to hopefully be ‘error-correcting’.
Fairness is still too optimistic. Errors are not always corrected!
The Epistemic View of Belief Merging: Can We Track the Truth?. (2010)¶
(Everaere, Patricia and Konieczny, Sébastien and Marquis, Pierre et al)
Summary:
Belief merging has been looked at from a synthesis view, which “aims at characterizing a base which best represents the beliefs of the input profile”
This paper takes the epistemic view: “the purpose of a belief merging process is to best approximate the true state of the world”
(This is the case with TD: existing approaches look at the ‘synthesis’ POV, whereas I am interested in the epistemic view)
Authors introduce a truth-tracking postulate for belief merging
Empirical analysis is discussed
Formalisms:
Propositional language \(\mathcal{L}\).
Each agent has a base \(K \subseteq \mathcal{L}\). Doesn’t seem that consistency of \(K\) is required.
A profile is a vector \((K_1,\ldots,K_n)\) of bases.
Probabilistic model:
For each world \(w_j\) and base \(K_i\), we have a binary random variable to represent \(w_j \vDash K_i\) or \(w_j \not\vDash K_i\) (i.e. \(w_j \in [K_i]\) or not).
Random variable \(\Omega^*\) ranges over set of worlds and represents the ‘true’ world
Agents are independent iff (roughly speaking) their bases are independently chosen, when we condition on the true world. That is, for a fixed world \(w^*\) and worlds \(w_1,\ldots,w_n\) for each agent, we have \(P(\bigwedge_{i=1}^{n}{w_i \vDash K_i} \mid \Omega^* = w^*) = \prod_{i=1}^{n}{P(w_i \vDash K_i \mid \Omega^* = w^*)}\)
Agents are homogenous iff (roughly speaking) they are equally reliable: there is a constant \(p\) such that for each world \(w_j\) and base \(K_i\), \(P(w_j \vDash K_i) = p\). In other worlds, for any world \(w_j\) the probability that an agent’s base is consistent with the world is the same.
Introduce different measures of reliability (R1 to R4)
Some aren’t strong enough for truth-tracking: e.g. they allow an agent to state just the tautologies (and therefore always be correct no matter the true world) and receive maximal reliability
R4 therefore considers incompetence as well as reliability. Roughly, the incompetence of agent \(i\) is the maximal probability that a world other than \(w^*\) is a model of \(K_i\).
For each there is some kind of result similar to Condorcet’s Jury Theorem: the probability that plurality/voting finds the true world has limit 1 as the number of agents goes to infinity (under conditions on the agents).
Truth-tracking (TT) postulate:
Consider a belief merging operator \(\Delta\), and \((E_n)_{n \in \mathbb{N}}\) a set of ‘widening’ profiles of independent, homogenous and R4 reliable agents (widening means \(E_n\) has \(n\) agents, and the models of the bases of the old agents stay the same).
TT stipulates \(P([\Delta(E_n)] = \{w^*\}) \to 1\) as \(n \to \infty\).
That is, \(\Delta\) finds exactly the true world with probability 1 in the limit.
They give examples of existing belief merging operators and see whether TT is satisfied
Empirical analysis for a TT operator
They look at probability convergence speed for different levels of agent incompetence and for different numbers of propositional variables in the language \(\mathcal{L}\).
Aggregation in Multi-Agent Systems and the Problem of Truth-Tracking (2007)¶
(Gabriella Pigozzi, Stephan Hartmann)
Summary:
Investigates methods for aggregating (propositional) beliefs of multiple agents, and how well the track the truth
Agents are assumed to be equally reliable
Refers to information fusion and belief merging literature
Setting is similar to judgment aggregation:
\(N\) agents each with a consistent and complete belief base \(K_i\).
An integrity constraint \(IC\) is placed on the aggregated belief base.
A fusion operator \(\mathcal{F}\) performs the aggregation given \(IC\) and \(\{K_i : i \in [N]\}\).
Authors define the majority fusion operator. It selects output belief base \(E\) by finding the models of \(IC\) with minimal Hamming distance to the models of the \(K_i\). Output is by definition guaranteed to satisfy \(IC\) (resolves the inconsistency issue of the discursive dilema)
Authors evaluate majority fusion against premise- and conclusion-based JA aggregation methods as the reliability of agents varies (reliability is a probability)
Majority fusion only performs better for \(p < 0.5\)
Logic-based approaches to information fusion (2006)¶
(Eric Grégoire and Sébastien Konieczny)
Survey of methods for aggregating conflicting information
For symbolic data, in a propositional logic framework
Assumptions:
Independent data sources
Equally reliable/important sources
Equally important propositions
Fusion can be applied in different epistemological contexts
Beliefs: inputs are what agents believe to be true of the real world
A special case is observations: e.g. sensors which are not fully reliable make observations about the world
Knowledge: inputs are what agents know to be the true world. Here the real world is a model of each agent’s base. Conjunction is the only sensible fusion operator
Goals: bases represent how the world should be, from the point of view of the agent. Fusion means finding overall goals acceptable to everyone. Related to preference aggregation in social choice
Regulations and laws: bases represent how the world should ideally be (e.g. in a legal context). Mostly handled in a non-monotonic logic framework
Evaluation criteria for fusion operators
Rationality postulates
Computational complexity
Strategy-proofness
Cautiousness: if two operators cannot be distinguished wrt the other criteria, the less cautious of the two might be more interesting, since it allows more conclusions to be drawn
Formal preliminaries
Standard propositional framework
Belief base: finite set of formulas. Usually assumed to be closed wrt logical consequence
Belief profile: multi-set of belief bases
Syntax-based operators:
Look at the actual formulas in each belief base
For a set of formulas \(K\) and integrity constraint \(IC\), define \(\text{maxcons}(K, IC)\) as the set of maximal (wrt set inclusion) subsets \(M \subseteq K \cup \{IC\}\) such that \(IC \in M\) and \(M\) is consistent. Write \(\text{maxcons}(E, IC) = \text{maxcons}(\cup_{K \in E}, IC)\)
Example operator: \(\Delta_{IC}(E) = \bigvee_{M \in \text{maxcons}(E, IC)}{\bigwedge{M}}\). In words, join together the integrity constraint with formulas from all agents. Then look at the maximal sets which are consistent (identifying each set with the conjunction of its formulas). Each is a plausible candidate for the merged beliefs, so finally take the disjunction of all of them
Model-based operators:
Each belief base is identified with its set of models
Syntactical form of beliefs is irrelevant
For each profile \(E\), suppose we construct a total preorder \(\le_E\) on the set of worlds, with the minimal world being the most preferable from the point of view of \(E\)
Then we simply take \(\Delta_{IC}(E)\) as a formula whose only model is the minimal model of \(IC\)
TODO: finish reading
On the logic of iterated belief revision (1997)¶
(Adnan Darwiche and Judea Pearl)
Summary:
Argues that AGM belief revision is too permissive when it comes to iterated belief revision
A revision step should update not only current beliefs but conditional beliefs: what would we belief upon receipt of future hypothetical information. This amounts to revision the belief revision strategy itself
Belief revision preliminaries:
Propositional language \(\mathcal{L}\). Belief sets are represented by sentences \(\psi\) (the actual belief set is \(Cn(\psi)\)), as are the pieces of information
An operator \(\circ\) maps a belief set \(\psi\) and information \(\mu\) to a new belief set \(\psi \circ \mu\)
AGM postulates (apparently this the KM (Katsuno and Medelezon) formulation of AGM in propositional logic):
\(\psi \circ \mu\) implies \(\mu\)
If \(\psi \wedge \mu\) is satisfiable then \(\psi \circ \mu \equiv \psi \wedge \mu\)
If \(\mu\) is satisfiable then \(\psi \circ \mu\) is also satisfiable
If \(\psi_1 \equiv \psi_2\) and \(\mu_1 \equiv \mu_2\) then \(\psi_1 \circ \mu_1 \equiv \psi_2 \circ \mu_2\)
\((\psi \circ \mu) \wedge \phi\) implies \(\psi \circ (\mu \wedge \phi)\)
If \((\psi \circ \mu) \wedge \phi\) is satisfiable, then \(\psi \circ (\mu \wedge \phi)\) implies \((\psi \circ \mu) \wedge \phi\)
Representation theorem due to KM:
Let \(W\) be sets of worlds of \(\mathcal{L}\). A Mapping assigning to each sentence \(\psi \in \mathcal{L}\) to a tpo \(\le_\psi\) on \(W\) is a faithful assignment if
\(w_1, w_2 \vDash \psi\) implies \(w_1 \approx_\psi w_2\)
\(w_1 \vDash \psi\) and \(w_2 \not\vDash \psi\) implies \(w_1 <_\psi w_2\)
\(\psi \equiv \phi\) implies \({\le_\psi} = {\le_\phi}\)
That is, all models of \(\psi\) rank equally (and minimally), models are ranked below non-models, and the tpo is the same for equivalent sentences
Theorem: \(\circ\) satisfies the AGM postulates if and only if there exists a faithful assignment such that \([\psi \circ \mu] = \min([\mu], {\le_\psi})\). That is, the models of the new belief set are exactly the minimal (‘most plausible’) models of \(\mu\) wrt the tpo corresponding to \(\psi\).
Conditional beliefs and epistemic states:
\(\beta\) is a conditional belief given \(\alpha\) for a belief set \(\psi\) if \(\psi \circ \alpha\) implies \(\beta\)
Some examples show that there are AGM-compatible operators which allow one to unintuitively drop or acquire conditional beliefs. The problem is that AGM does not constrain what happens for multiple revisions.
Authors claim that belief revision should be performed on epistemic states, not just sentences. There is no precise definition given of an epistemic state, but it at the very least has an associated belief set \(Bel(\psi)\), which is a sentence in \(\mathcal{L}\).
Epistemic state versions of the AGM postulates are given: changes are to replace \(\psi\) with \(Bel(\psi)\), and weaken the ‘syntax independence’ property: if \(Bel(\psi_1) \equiv Bel(\psi_2)\) we do not necessarily have \(\psi_1 \circ \mu \equiv \psi_2 \circ \mu\) (since \(\psi_1\) and \(\psi_2\) might differ in the conditional beliefs inherent in them).
Analogous representation to KM with tpo on set of worlds for each epistemic state.
Principle of ‘change minimisation’ also leads to unintuitive examples when it comes to conditional beliefs.
Postulates for iterated revision:
(Here \(\psi\) is actually an epistemic state, but the authors also write \(\psi\) for the associated belief set sentence in the statement of the postulates.)
If \(\alpha \vDash \mu\), then \((\psi \circ \mu) \circ \alpha = \psi \circ \alpha\).
That is, receiving first some evidence \(\mu\) and then some more specific evidence \(\alpha\), the first piece of evidence is redundant and the resulting belief set is the same as after a single revision by \(\alpha\).
If \(\alpha \vDash \neg\mu\), then \((\psi \circ \mu) \circ \alpha = \psi \circ \alpha\).
That is, the second piece of evidence prevails when receiving contradictory information.
If \(\psi \circ \alpha \vDash \mu\), then \((\psi \circ \mu) \circ \alpha \vDash \mu\).
Conditional belief of \(\mu \mid \alpha\) should not be given up after revising by \(\mu\) first.
If \(\psi \circ \alpha \not\vDash \neg\mu\), then \((\psi \circ \mu) \circ \alpha \not\vDash \neg\mu\).
No \(\mu\) can ‘contribute to its own demise’. If we didn’t have the conditional belief \(\neg\mu \mid \alpha\), neither should we have this after revising by \(\mu\).
Representation theorem:
On the semantic side, the above postulates for iterated revision tell us the relation between the tpos \(\le_\psi\) and \(\le_{\psi \circ \mu}\).
Theorem: \(\circ\) satisfies the modified AGM postulates and the four above postulates iff the following properties hold, where \({\le_\psi}\) is the tpo on worlds corresponding to the epistemic state \(\psi\)
\(w_1, w_2 \vDash \mu\) implies \(w_1 \le_\psi w_2\) iff \(w_1 \le_{\psi \circ \mu} w_2\).
\(w_1, w_2 \vDash \neg\mu\) implies \(w_1 \le_\psi w_2\) iff \(w_1 \le_{\psi \circ \mu} w_2\).
If \(w_1 \vDash \mu\) and \(w_2 \vDash \neg\mu\), then \(w_1 <_\psi w_2\) implies \(w_1 <_{\psi \circ \mu} w_2\).
If \(w_1 \vDash \mu\) and \(w_2 \vDash \neg\mu\), then \(w_1 \le_\psi w_2\) implies \(w_1 \le_{\psi \circ \mu} w_2\).
Concrete example of an operator satisfying all the postulates, based on Sphon’s ordinal conditional functions.
Trust as a Precursor to Belief Revision (2018)¶
(Booth, Richard and Hunter, Aaron)
Summary:
Describes how to use trust information between agents as a pre-processing step in AGM belief revision
Model:
Consider a propositional language over a set of atomic propositions \(\bm{F}\), and a set of agents \(\bm{A}\)
The set of states is \(2^\bm{F}\) (i.e. a valuation is identified with the set of atoms which are made true)
For an agent \(A\) with belief set \(K\), the state partition for agent \(B\) is \(\Pi_{B,K}\)
Intuition: the cells of \(\Pi_{B,K}\) consist of states that \(A\) does not trust \(B\) to distinguish between
For a state \(s\) and partition \(\Pi\), let \(\Pi(s)\) denote the unique set of states in \(\Pi\) which contains \(s\)
Trust expansion:
For a state partition \(\Pi\) and formula \(\phi\), write
\[\Pi[\phi] = \bigcup \{\Pi(s) \mid s \vDash \phi\}\]This is the set of possible states when information \(\phi\) is received from an agent whose trust partition is \(\Pi\): look at all models of \(\phi\), and expand to fill the relevant cells of \(\Pi\)
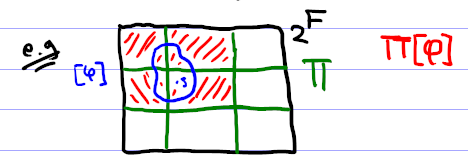
Can define trust-sensitive revision similar to AGM revision, based on a faithful assignment function \(\preceq\) and using \(\Pi[\phi]\) instead of just the models of \(\phi\). Or…
Can expand \(\phi\) on a syntactic level: \(\phi_K^A(B)\) is the formula true in exactly the states in \(\Pi_{B,K}[\phi]\) (this is unique up to logical equivalence, and unique if we require \(\phi_K^a(B)\) to be in disjunctive normal form).
Trust-sensitive revision: if each agent \(A\) has an AGM revision operator \(*_A\), we can define, for each other agent \(B\), the trust-sensitive revision operator \(*_A^B\) by
\[K *_A^B \phi = K *_A \phi_K^A(B)\]
Selective revision:
This fits into the scheme of selective revision: \(\circ\) is a selective revision operator if there is some AGM operator \(*\) and a function \(f\) mapping \((K, \phi)\) to a formula \(f_K(\phi)\) such that
\[K \circ \phi = K * f_K(\phi) \]In this case \(f\) additionally depends on agents \(A\) and \(B\) and the state partition \(\Pi_{B,K}\): \(f_K(\phi) = \phi_K^A(B)\)
Axioms already have been given for the transformation function \(f\)
Falsity preservation: \(f(\perp) = {\perp}\)
Implication: \(\phi \vdash f(\phi)\)
Idempotency: \(f(f(\phi)) = f(\phi)\)
Extenstionality: if \(\phi \equiv \psi\) then \(f(\phi) \equiv f(\psi)\)
Disjunctive distribution: \(f(\phi \vee \psi) \equiv f(\phi) \vee f(\psi)\)
The axioms correspond to properties of the selective revision operator \(\circ\)
In light of extensionality, \(f\) can be defined as mapping sets of states to sets of states; in this case the above axioms corresponding exactly to the Kuratowski closure axioms. This means that \(f\) defines a topology on \(2^\bm{F}\), and \(f\) is the closure operator. \(f\) is called a Kuratowski transformation function in this case.
Result: every \(f\) derived from a state partition satisfies the above axioms
Authors give some additional properties of \(f\) that hold for state partition transformation functions but not for Kuratowski transformation fucntions in general
Result: \(f\) is derived from some state partition if and only if it is a Kuratowski transformation function satisfying
Pawlak: \(f(\neg f(\phi)) \equiv \neg f(\phi)\)
In topological terms, Pawlak says that every open set is also closed. So this kind of topology characterises the trust-based transformation functions
Result: representation result for trust-sensitive revision operators. Uses properties lifted from \(f\)
The success postulate:
Trust-sensitive revision clearly violates AGM’s success postulate
Authors introduce a few weaker version which are also violated (although this is not a problem)
A very weak postulate called “Feeble success” is satisfied by trust-sensitive revision. This property does not in general hold for all Kuratowski selective revision operators
Related: authors introduce manipulability postulates (think strategyproofness…) which are violated in general by trust-sensitive revision. A weaker version holds for all Kuratowski selective operators.
Author’s ideas for future work to incorporate stength of trust:
In current model, \(A\) either trusts \(B\) to distinguish between a pair of states \(s, t\), or does not. To give instead a more fine-grained assessment of \(B\), \(A\) could have a distance function \(d\), such that the larger \(d(s, t)\), the more able agent \(B\) is able to distinguish between states \(s\) and \(t\)
In particular, \(d\) should be a psuedo-ultrametric:
\(d(x, x) = 0\)
\(d(x, y) = d(y, x)\)
\(d(x, z) \le \max\{d(x,y), d(y,z)\}\)
(a pseudo-metric since we allow \(d(x,y) = 0\) for \(x \ne y\), and an ultrametric due to the third property, which is a stronger version of the triangle inequality)
One can show that the set \(\{B_r(x) \mid x \in 2^\bm{F}\}\) forms a partition of \(2^\bm{F}\), where \(r > 0\) and \(B_r(x) = \{y \in 2^\bm{F} \mid d(x, y) \le r\}\) is the (closed) ball of radius \(r\) at \(x\). The partitions get coarser as \(r\) increases; we become more demanding as more states are lumped together
If agents \(B\) and \(C\) provide conflicting reports, find the smallest \(r\) such the trust-expanded reports are consistent. One can then use this \(r\) to perform trust-sensitive revision as before
How to revise a total preorder (2011)¶
(Booth, Richard and Meyer, Thomas)
Summary:
Iterated revision uses tpos to represent conditional beliefs, which allows a unique belief set to be identified after receiving new evidence
However, existing approaches to iterated revision (e.g. DP postulates) do not specify how to uniquely revise the tpo itself
This paper enriches the epistemic state so as to determine the new tpo (and therefore belief set) uniquely
Enrichment of the epistemic state:
Let \(W\) be the set of propositional worlds, and \(W^\pm = \{w^\epsilon \mid w \in W, \epsilon \in \{+, 1\}\}\)
Epistemic state consists of a tpo \(\le\) on \(W\) and a tpo \(\preceq\) on \(W_\pm\), related by the following properties:
\(x \le y\) iff \(x^+ \preceq y^+\) iff \(x^- \preceq y^-\).
\(x^+ \prec x^-\).
\(\preceq\) can be visualised in quite a nice way using intervals for each \(x^+, x^-\) (see paper)
Revision operators from \(\preceq\):
Given new evidence \(\alpha\) and our exiting tpo \(\le\) on \(W\), the aim is to produce a new tpo \(\le_\alpha^*\) on \(W\). This can be done using the enriched epistemic state.
For a sentence \(\alpha\) and world \(x\), write
\[r_\alpha(x) = \begin{cases} x^+, & x \vDash \alpha \\ x^-, & x \vDash \neg\alpha \end{cases}\]Then set \(x \le_\alpha^* y\) iff \(r_\alpha(x) \preceq r_\alpha(y)\).
This also defines the new belief set: the sentences true in the minimal worlds wrt \(\le_\alpha^*\).
It may be the case that \(\alpha\) is not believed after revision, i.e. the success postulate fails, and this is non-prioritised revision.
Representation theorem given for operators generated in this way.
Link with social choice and preference aggregation:
Each sentence \(\alpha\) induces a tpo \(\le_\alpha\) on \(W\) with at most two ranks, where we simply rankg the \(\alpha\) worlds equal to each other and strictly below the \(\neg\alpha\) worlds
Revising \(\le\) by \(\alpha\) now amounts to aggregating two tpos: \(\le\) and \(\le^\alpha\).
Can look at social-choice-style properties:
All operators generated from \(\preceq\) satisfy Pareto and a version of IIA
Sentence-level formulation:
Given a tpo \({\le}\) over \(W\) and a sentence \(\beta\), define \({\le} \circ \beta\) as the set of sentences true in each world in \(\min([\beta], {\le})\)
Representation theorem for the above family of revision operators using the \(\circ\) operation and syntax-level properties
Discussion on notions of strict preference relation over worlds derived from \({\preceq}\)
Merging with unknown reliability (2021)¶
(Paolo Liberatore)
Konieczny and Perez style belief merging with agent weights
\[\Delta_\mu^{d, \vec{w}}(\phi_1,\ldots,\phi_m) = \text{argmin}_{\omega \in [\mu]} \sum_{i=1}^{m}w_i d(\omega, \phi_i)\]where as usual, \(d(\omega, \phi) = \min\{d(\omega, \omega') \mid \omega' \vDash \phi\}\)
For a set of weight vectors \(\mathcal{W} \subseteq \mathbb{R}^m\),
\[\Delta_\mu^{d, \mathcal{W}}(\phi_1,\ldots,\phi_m) = \bigcup_{\vec{w} \in \mathcal{W}} \Delta_\mu^{d, \vec{w}}(\phi_1,\ldots,\phi_m)\]is the union of all possible merging outputs for weights in \(\mathcal{W}\)
Idea: actual reliability weights are unknown, but they are known to lie in \(\mathcal{W}\)
If \(\mathcal{W} = \mathbb{N}^m\) and we use the “drastic distance” \(d(\omega, \omega') = \mathbb{1}[\omega \ne \omega']\), the merging outcomes are the union of all models of maximally consistent subsets of \(\{\mu,\phi_1,\ldots,\phi_m\}\)
Some results for the Hamming distance, geometric interpretation, and an algorithm for merging
Consideration of merging postulates
A simple modal logic for belief revision (2005)¶
(Bonanno, Giacomo)
Background: authors aim to capture the qualitative Bayes’ rule for belief revision: if \(\text{supp}(P_0)\) and \(\text{supp}(P_1)\) denote the support of prior and posterior probability distributions representing beliefs before and after receiving evidence \(E\), then
\[\text{supp}(P_0) \cap E \ne \emptyset \implies \text{supp}(P_1) = \text{supp}(P_0) \cap E\](where here support is the set of states assigned non-zero probability. In particular the authors assume that probability measures assign probability to all singleton sets)
This corresponds to minimal change ideas in AGM belief revision
Modal logic with three modal operators
\(B_0\phi\): the agent believes \(\phi\) at time 0
\(I_\phi\): the agent was (truthfully) informed of \(\phi\) at time \(0 < t < 1\)
\(B_1\phi\): the agent believes \(\phi\) at time 1
Semantics: model is \((\Omega, \mathcal{B}_0, \mathcal{B}_1, \mathcal{I}, v)\), with \(\mathcal{B}_i\) and \(\mathcal{I}\) relations on \(\Omega\). Belief modalities are standard, but \(I\) has non-standard semantics
\[\begin{aligned} \omega \vDash B_0\phi &\iff \mathcal{B}_0(\omega) \subseteq \|\phi\| \\ \omega \vDash B_1\phi &\iff \mathcal{B}_1(\omega) \subseteq \|\phi\| \\ \omega \vDash I\phi &\iff \mathcal{I}(\omega) = \|\phi\| \end{aligned}\]Axioms:
“Qualified acceptance”: \((I\phi \wedge \neg B_0\neg\phi) \rightarrow B_1\phi\)
“Persistence”: \((I\phi \wedge \neg B_0 \neg \phi) \rightarrow (B_0\psi \rightarrow B_1\psi)\)
“Minimality”: \((I\phi \wedge B_1\psi) \rightarrow B_0(\phi \rightarrow \psi)\)
On the semantic side, these axioms characterise QBR for all states \(\omega\), with \(\mathcal{B}_i(\omega)\) replacing \(\text{supp}(P_i)\). That is,
QA, Pers. and Min. are valid in a frame \((\Omega, \mathcal{B}_0, \mathcal{B}_0, \mathcal{I})\) if and only if for all \(\omega \in \Omega\):
\[\mathcal{B}_0(\omega) \cap \mathcal{I}(\omega) \ne \emptyset \implies \mathcal{B}_1(\omega) \mathcal{B}_0(\omega) \cap \mathcal{I}(\omega)\]
Sound and complete axiomatisation is given for class of all frames. Authors add a universal modality \(A\) to the language (where \(\omega \vDash A\phi\) iff \(\|\phi\| = \Omega\)) to deal with non-standard semantics of \(I\)
Sound and complete axiomatisation for QBR frames is obtained by adding the three axioms (QA, Pers., Min.) to the logic
Authors consider additional axioms for belief (e.g. KD45) and show that these characterise additional properties on frames (transitivity, reflexivity, etc…)
Comparison with AGM revision:
There are analogues of the AGM postulates in the present modal language
For any model and state \(\omega\) with \(\omega \vDash I\phi\), one can form belief sets \(K = \{\psi \mid \omega \vDash B_0\psi\}\) and \(K^*_\phi = \{\psi \mid \omega \vDash B_1\phi\}\). Assuming the analogues of the AGM postulates hold at \(\omega\), the authors show that the revision operator \(*\) so defined satisfies the AGM postulates.
Remarks on iterated revision: it is possible to extend the language to have modalities \(B_t\) and \(I_{t,t+1}\) for all \(t \in \mathbb{N}\). Then natural generalisations of QA, Pers. and Min. characterise frames with the iterated QBR property
Trust-based belief change (2014)¶
(Lorini, Emiliano and Jiang, Guifei and Perrussel, Laurent)
Language DL-BT (dynamic logic of graded belief and trust):
\[\phi ::= p \mid \neg\phi \mid \phi \wedge \phi \mid {K}_i\phi \mid {B}_i^{\ge \alpha}\phi \mid {T}_{i,j}^{\alpha}\phi \mid [\star_i^f\phi]\phi\]where \(i, j\) are agents, \(\alpha\) is an integer from a fixed scale, and \(f\) represents a function which assigns each agent a “trust-based belief change policy”.
Semantics for static fragment:
Equivalence relation for each agent (accessibility relation for \(K\))
Ordinal ranking function \(\kappa\) assigning each state and agent an implausibility score \(\alpha\) (used for \(B\))
For each \(\alpha\) and agents \(i, j\), a neighbourhood function \(N_{i,j}\). Idea is that \(N_{i,j}(x, \alpha)\) is the set of states on which \(i\) trusts \(j\) to degree \(\alpha\), at state \(x\).
Some natural constraints relating accessibility relations and \(\kappa\), and constraints on \(N\)
Revision policies update the \(\kappa\) rankings. This defines the model update for the semantics of the dynamic part of the language. Note that the trust relationships are not affected.
Authors consider different policies:
“Additive policy”: if \(i\) reports \(\phi\), then; i) if \(j\) trusts \(i\) on \(\phi\), the \(\phi\) worlds are shifted down in \(j\)s ranking, and the \(\neg\phi\) worlds are shifted up by an amount depending on the degree of trust \(i\) has in \(j\) on \(\phi\); ii) otherwise the ranking stays the same.
“Compensatory policy”: similar but somehow different to the additive one…
Axiomatisation:
KT45 for knowledge
Some axioms for graded belief (normality, consistency, positive and negative introspection of beliefs, knowledge implies belief with maximum grade, and belief to degree \(\alpha + 1\) implies belief to degree \(\alpha\)
Axioms for graded trust
Reduction axioms for dynamic part. Straightforward for knowledge, trust under either revision policy, but very complicated for belief
Reasoning about belief, evidence and trust in a multi-agent setting (2017)¶
(Liu, Fenrong and Lorini, Emiliano)
DL-BET: dynamic logic of belief, evidence and trust
Multiple agents
Modal operators for knowledge, belief, evidence and trust
\(E_{ij}\phi\) means that agent \(i\) has obtained evidence \(\phi\) on the basis of information from agent \(j\)
\(T_{ij}\phi\) means that agent \(i\) trusts agent \(j\) on \(\phi\)
Each agent has an epistemic type \((x, y)\), where
\(x \in \mathbb{N}\) is the minimum number of pieces of evidence for \(\phi\) (or \(\neg\phi\)) the agent must collect before believing it is true
\(y \in (\frac{1}{2}, 1]\) is a quota value: the ratio of pieces of evidence for/against \(\phi\) must be at least \(y\) before \(\phi\) can be believed
Four dynamic operators:
Agent \(i\) publicly announces \(\phi\)
Agent \(i\) stops trusting \(j\) on \(\phi\)
Agent \(i\) comes to trust \(j\) on \(\phi\)
Agent \(i\) assesses (and possibly changes) their belief in \(\phi\)
Epistemic type comes into play with an abbreviation \(R_i\phi\), standing for “agent \(i\) has sufficient reason to believe \(\phi\). This is used in the “assessment” event
Semantics:
Relational semantics for knowledge and belief (equivalence relation for knowledge)
Neighbourhood semantics for evidence and trust
Type for each agent is fixed in the model (and does not change with dynamic events)
Dynamics:
Mostly as expected
Assessment: if \(i\) has sufficient reason to believe \(\phi\) and does not believe \(\neg\phi\), then beliefs are strengthened to include \(\phi\) (similar for \(\neg\phi\)). If \(i\) has sufficient reason to believe \(\phi\) but believes \(\neg\phi\), previous beliefs are thrown out and agent believes the \(\phi\) worlds in the current cell of the \(K\) equivalence relation (similar for \(\neg\phi\)).
Authors say this is belief expansion in the first case, and belief revision in the second.
Axiomatisation
A logic of trust and reputation (2010)¶
(Herzig, Andreas and Lorini, Emiliano and Hubner, Jomi F and Vercouter, Laurent)
Formal modelling of the “cognitive theory of trust by Castelfranchi and Falcone” (C & F) in modal logic
C & F defines trust as “an individual belief of the truster about some properties of the trustee that are relevant for the achievement of a given goal”
More formally, \(i\) trusts \(j\) in relation to an action \(\alpha\) with respect to a goal \(\phi\) if \(i\) has the goal \(\phi\) and believes that: i) \(j\) is capable of performing \(\alpha\); ii) \(j\)s performing of \(\alpha\) will ensure \(\phi\); iii) \(j\) intends to perform \(\alpha\)
This appears to be more fine-grained than trust in other logical modellings I have seen: trust is built from the more primitive concepts of beliefs, choices, actions and goals
Logic:
Syntax:
\(G\phi\) means \(\phi\) will always hold in the future (\(F\phi = \neg G \neg \phi\) is the dual operator)
\(\mathsf{After}_{i:\alpha}\phi\) means \(\phi\) will hold immediately after agent \(i\) performs actions \(\alpha\)
\(\mathsf{Does}_{i:\alpha}\phi\) means \(i\) is going to perform \(\alpha\) and \(\phi\) will hold afterwards
\(\mathsf{Bel}_i\phi\) means \(i\) believes \(\phi\)
\(\mathsf{Choice}_i\phi\) means \(i\) has chosen \(\phi\) as a goal
Note that trust is not built into the language (this is expected: as described above, trust is a derived notion in the C & F theory)
Semantics: relational semantics with a bunch of constraints
Axiomatisation given
Trust:
“Occurrent trust”: \(i\) trusts \(j\) to perform \(\alpha\) in order to achieve goal \(\phi\):
\[\mathsf{OccTrust}(i,j,\alpha,\phi) := \\ \quad \mathsf{Choice}_i{F\phi} \wedge \mathsf{Bel}_i( \mathsf{After}_{j:\alpha}\phi \wedge \neg\mathsf{After}_{j:\alpha}\bot \wedge \mathsf{Choice}_j\mathsf{Does}_{j:\alpha}\top ) \]As a theorem of the axiomatisation, the conjunction of the second and third conjuncts inside \(\mathsf{Bel}_i\) is equivalent to \(\mathsf{Does}_{j:\alpha}\top\) (i.e. \(j\) is capable and willing to perform \(\alpha\) if and only \(j\) actually does perform \(\alpha\), so the definition can be simplified
Different notion of “dispositional trust”: \(i\) is disposed to trust \(j\) if \(i\) believes it might someday need \(j\) to perform some action to achieve a goal that \(i\) might someday have.
Authors model reputation similar to trust, but as a relation between groups of agents (trusters) and a single agent (trustee)
For each set of agents \(I\) with \(|I| \ge 2\), new modality \(\mathsf{Public}_I\phi\) means \(\phi\) is public belief among group \(I\)
Definition given for \(j\) to have reputation among group \(I\) to be able to ensure \(\phi\) by performing \(\alpha\) in circumstances \(\kappa\) (similar to dispositional trust, I think…)